BentoML 0.13.1
1. 모델 학습
꽃 품종 데이터셋인 Iris 데이터를 분류하기 위한 SVM 모델을 학습한다.
Scikit-learn을 통해 데이터셋을 불러오고 모델학습까지 손쉽게 할 수 있다. 그리고 모델을 pickle로 저장한다.
# train.py from sklearn import svm from sklearn import datasets import pickle # Load training data iris = datasets.load_iris() X, y = iris.data, iris.target # Model Training clf = svm.SVC(gamma='scale') clf.fit(X, y) with open("model.pkl", 'wb') as f: pickle.dump(clf, f)
2. 모델 서빙 - 로컬 배포
모델 학습을 통해 저장된 model.pkl 파일을 불러와 BentoML로 Packing한다.
BentoService를 상속받아 api들을 손쉽게 정의할 수 있다.
# bento_service.py import pandas as pd from bentoml import env, artifacts, api, BentoService from bentoml.adapters import DataframeInput from bentoml.frameworks.sklearn import SklearnModelArtifact @env(infer_pip_packages=True) @artifacts([SklearnModelArtifact('model')]) class IrisClassifier(BentoService): """ A minimum prediction service exposing a Scikit-learn model """ @api(input=DataframeInput(), batch=True) def predict(self, df: pd.DataFrame): """ An inference API named `predict` with Dataframe input adapter, which codifies how HTTP requests or CSV files are converted to a pandas Dataframe object as the inference API function input """ return self.artifacts.model.predict(df)
predict라는 api를 정의하였고 이는 /predict 라는 라우터를 생성해준다.
이제 정의된 BentoService를 통해 Bento로 Packing 하면된다.
# bento_packer.py import pickle from bento_service import IrisClassifier with open("model.pkl", "rb") as f: clf = pickle.load(f) iris_classifier_service = IrisClassifier() # Pack the newly trained model artifact iris_classifier_service.pack('model', clf) # Save the prediction service to disk for model serving saved_path = iris_classifier_service.save()
> python bento_packer.py # [2022-10-13 21:33:30,759] INFO - BentoService bundle 'IrisClassifier:20221013213330_2A8388' saved to: /Users/suwan/bentoml/repository/IrisClassifier/20221013213330_2A8388
그러면 바로 로컬 환경에서 모델을 서빙할 수 있다.
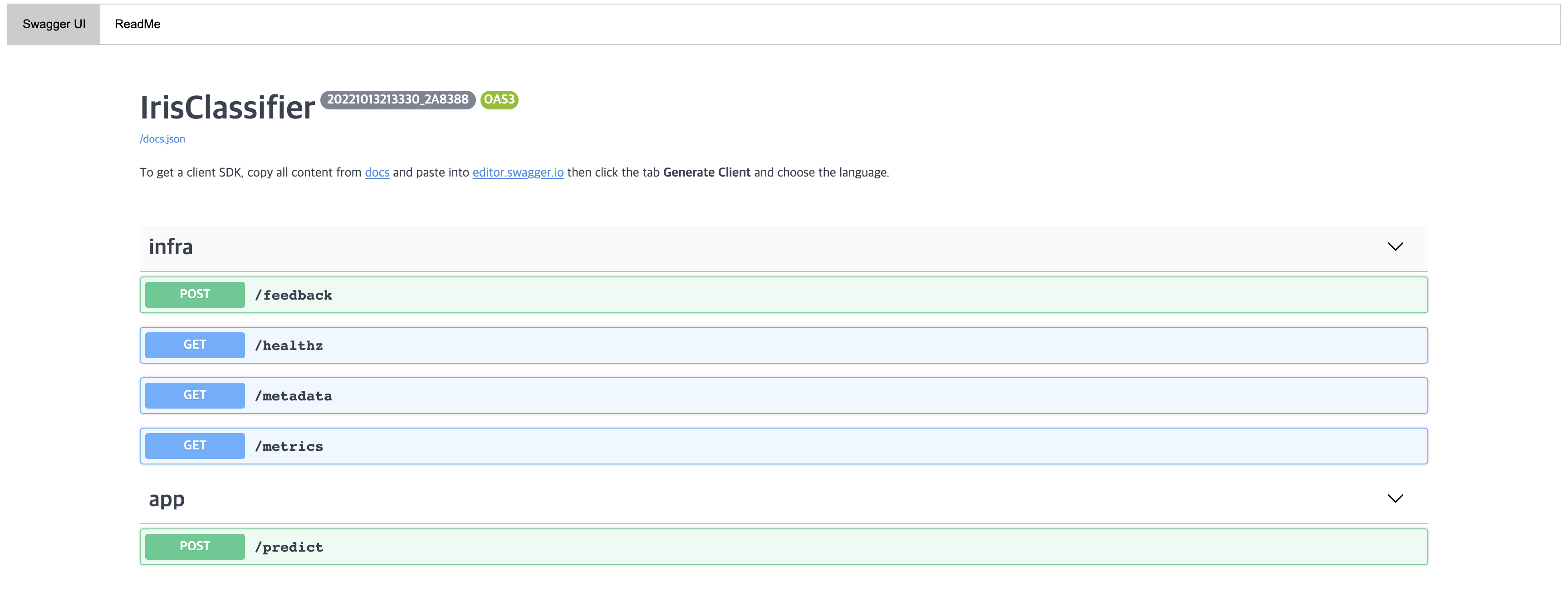
bentoml serve IrisClassifier:latest위 명령어를 실행한 뒤 http://0.0.0.0:5000/ 로 이동하면 아래와 같은 화면을 볼 수 있다.

그리고 보이는 /feedback, /healthz, /metadata, /metrics 는 IrisClassifier에서 상속받은 BentoService에 이미 정의되어 있던 API들이다.
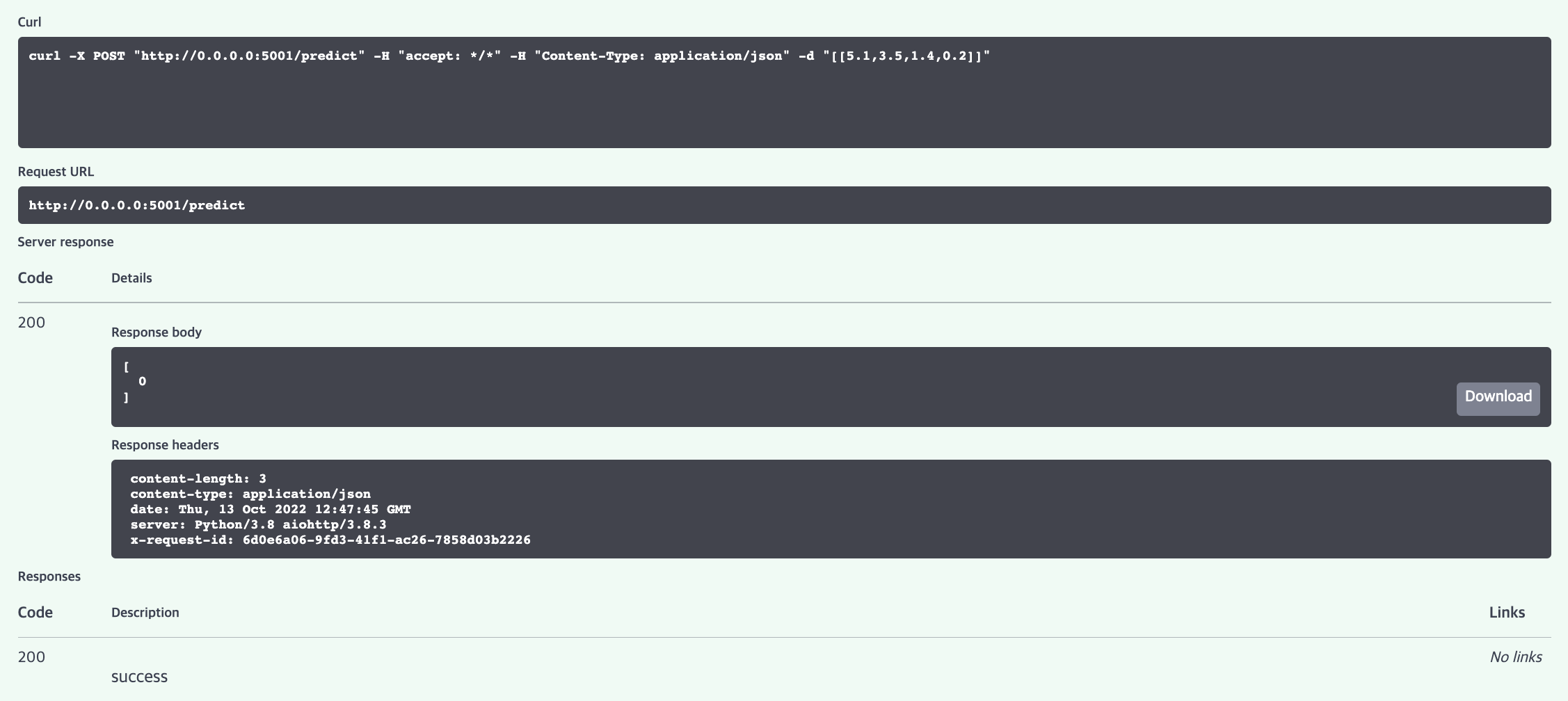
우리가 정의한 /predict 를 테스트 해보자. 아래와 같이 Request body에 [[5.1, 3.5, 1.4, 0.2]] 와 같이 입력하고 Execute 버튼을 누르면 된다.
그러면 아래와 같이 [0] 이 반환되는 것을 확인할 수 있다.
지금까지의 내용은 로컬 환경에 모델을 서빙한 뒤 테스트 했다. 이보단 쿠버네티스 환경에 업로드 하여 제한된 CPU, Memory로 설정한 뒤 성능을 테스트 하고자 한다.
3. 모델 서빙 - 쿠버네티스 배포
쿠버네티스에 배포하기 위해선 앞선 IrisClassifier를 도커 이미지로 빌드하여 도커 레지스트리에 업로드하여야한다.
도커 이미지로 빌드
saved_path=$(bentoml get IrisClassifier:latest --print-location --quiet) docker build -t ssuwani/iris-classifier $saved_path # 여기서 ssuwani는 나의 DockerHub의 username이다. 각자의 username으로 변경
도커 레지스트리에 업로드
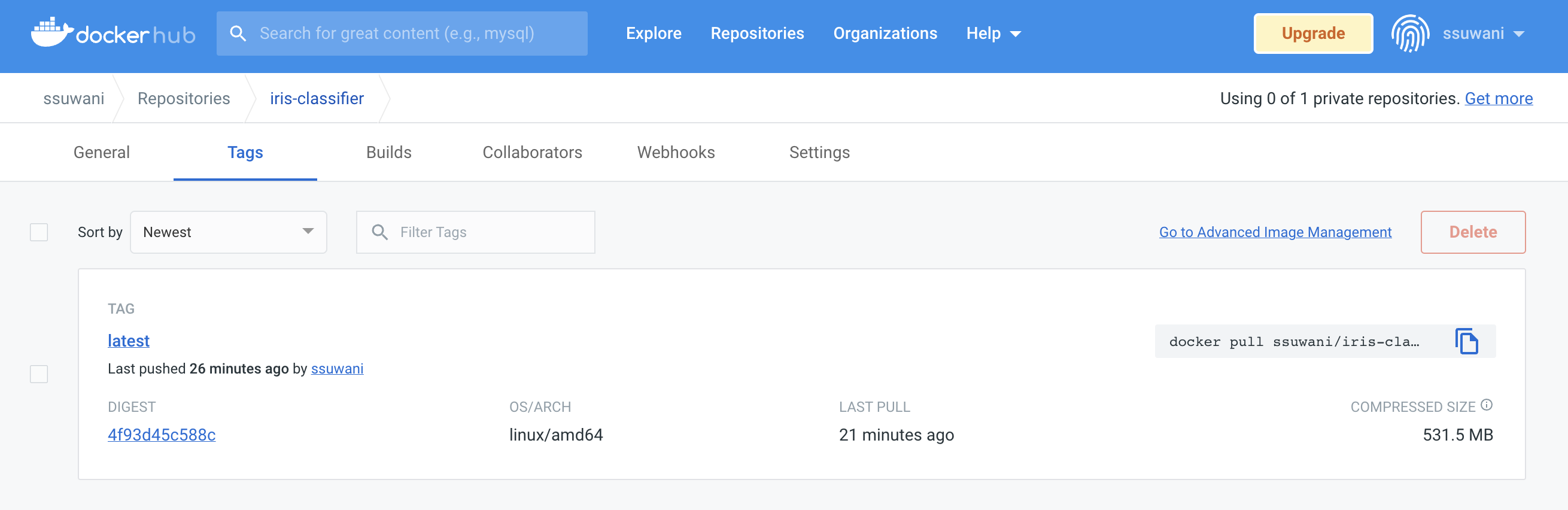
docker login -u ssuwani -p <password> docker push ssuwani/iris-classifier
그러면 아래와 같이 Docker Hub의 개인 계정에 잘 올라간 것을 확인할 수 있다.
이제 업로드한 도커 이미지를 통해 Deployment를 정의할 수 있다. 그리고 서비스도 정의하면 된다.
Deployment를 정의할 때 resources 를 통해 CPU와 Memory를 제한하였다.
#iris-classifier.yaml apiVersion: v1 kind: Service metadata: labels: app: iris-classifier name: iris-classifier spec: ports: - name: predict port: 5010 targetPort: 5000 selector: app: iris-classifier type: LoadBalancer --- apiVersion: apps/v1 kind: Deployment metadata: labels: app: iris-classifier name: iris-classifier spec: selector: matchLabels: app: iris-classifier template: metadata: labels: app: iris-classifier spec: containers: - image: ssuwani/iris-classifier imagePullPolicy: IfNotPresent name: iris-classifier ports: - containerPort: 5000 resources: requests: memory: "1Gi" cpu: "1" limits: memory: "1Gi" cpu: "1"
이제 업로드하자.
kubectl apply -f iris-classifier.yaml
deployment와 service를 조회해보자.
kubectl get po,svc
그리고 <EXTERNAL-IP>/<PORT> 로 접근 시 로컬에 배포했던 것과 같은 BentoML의 Swagger UI 화면을 확인할 수 있다.
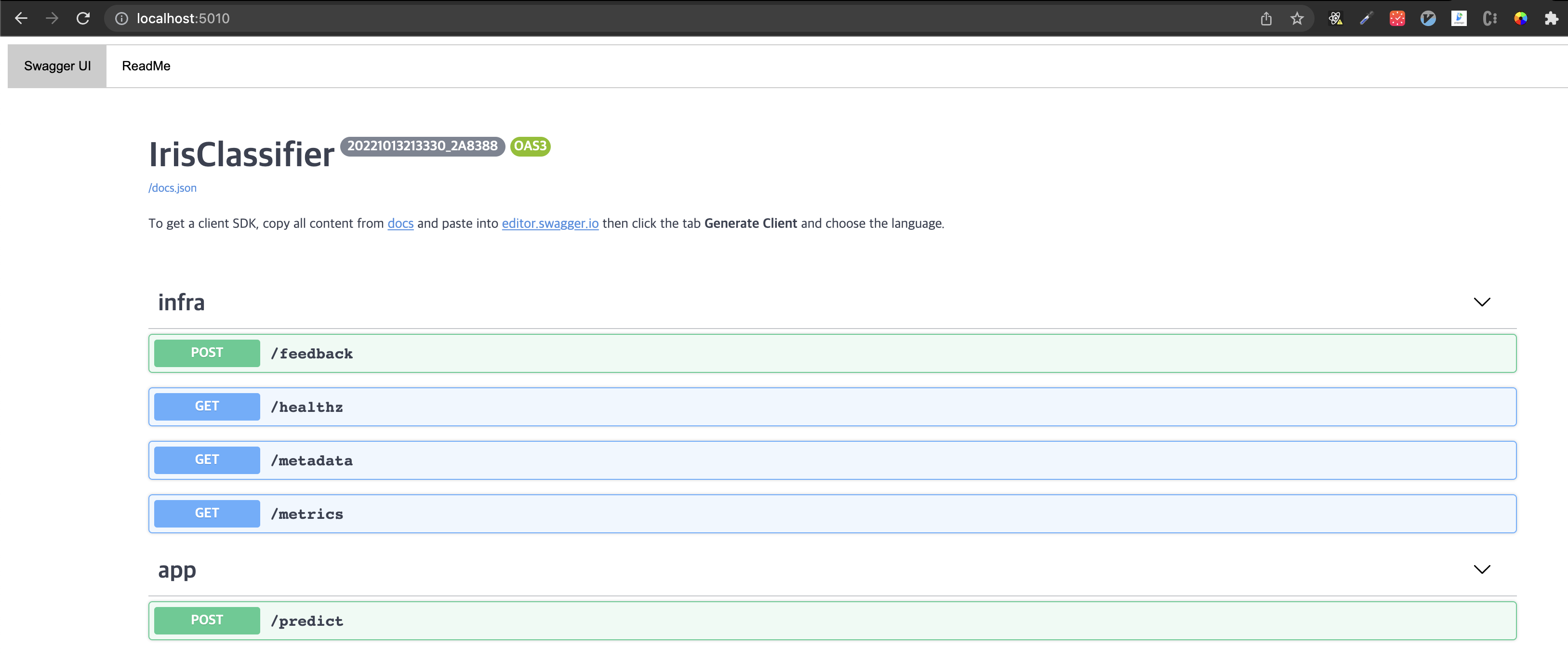
당연히 앞서 테스트해보았던 healthz, predict도 잘 동작한다.
4. 성능 테스트
성능 테스트를 위해선 locust를 사용하고자 한다. locust를 쿠버네티스에 올려서 진행할 수도 있지만 부하를 발생시키는 것 정도는 로컬에서 진행함에 무리가 없을꺼라 판단하여 로컬에서 locustfile를 정의하여 테스트 하고자 한다.
Locust 설치
pip install locust/predict로 post를 보내는 locustfile을 정의해야 한다.
# locustfile.py from locust import HttpUser, task, between class QuickstartUser(HttpUser): @task def hello_world(self): self.client.post("/predict", data='[[5.1, 3.5, 1.4, 0.2]]')
이제 아래 명령어로 locust를 실행할 수 있다.
locust
이제 http://0.0.0.0:8089/ 로 이동하면 아래와 같은 화면을 볼 수 있다.
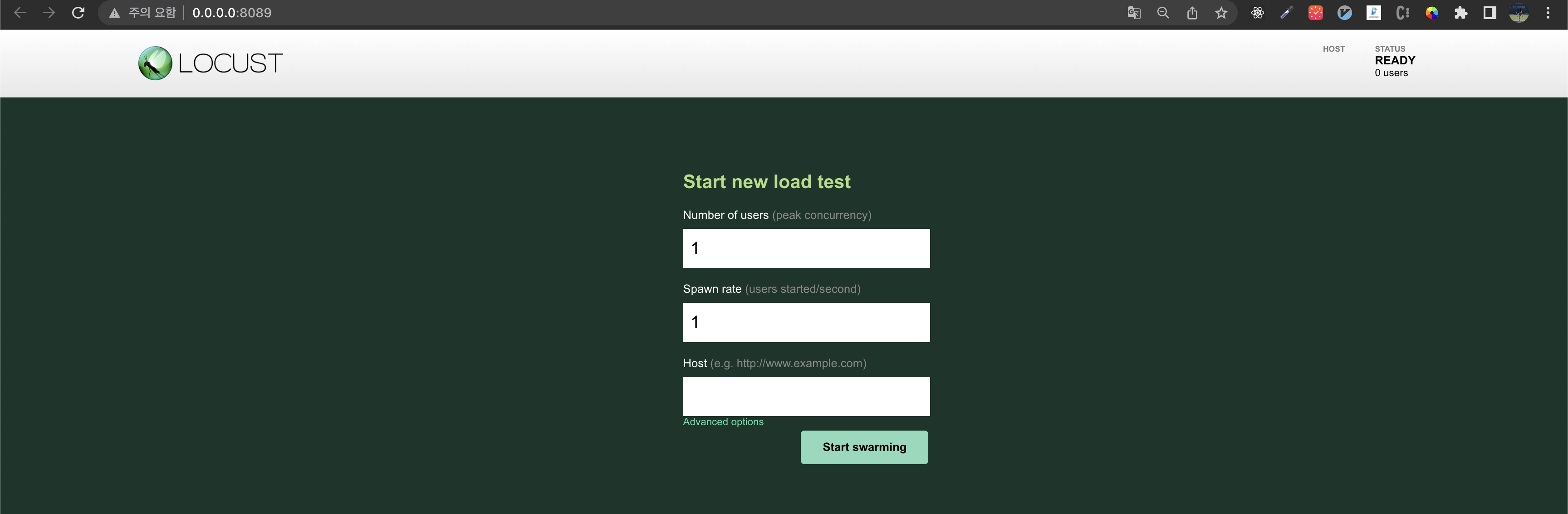
Number of users는 말그대로 몇명의 user가 요청하는 상황을 가정하는 지이고 Spawn rate는 초당 몇명의 유저를 증가시킬지이다. 처음에는 1명의 유저부터 Number of users에 정의한 숫자만큼의 user 상황을 가정하도록 하게되는데 1로 두면 1초에 1명씩 증가한다.
만약 Number of numbers: 100, Spawn rate: 2이면 100명이 될떄까지 약 50초가 소요된다.
그리고 Host는 http://localhost:5010 로 입력하면 된다. 그리고 Start swarnmig을 클릭한 뒤 Charts를 클릭해보면 다음과 같은 화면이 나오면 정상적으로 로드 테스트가 시작된 것이다.
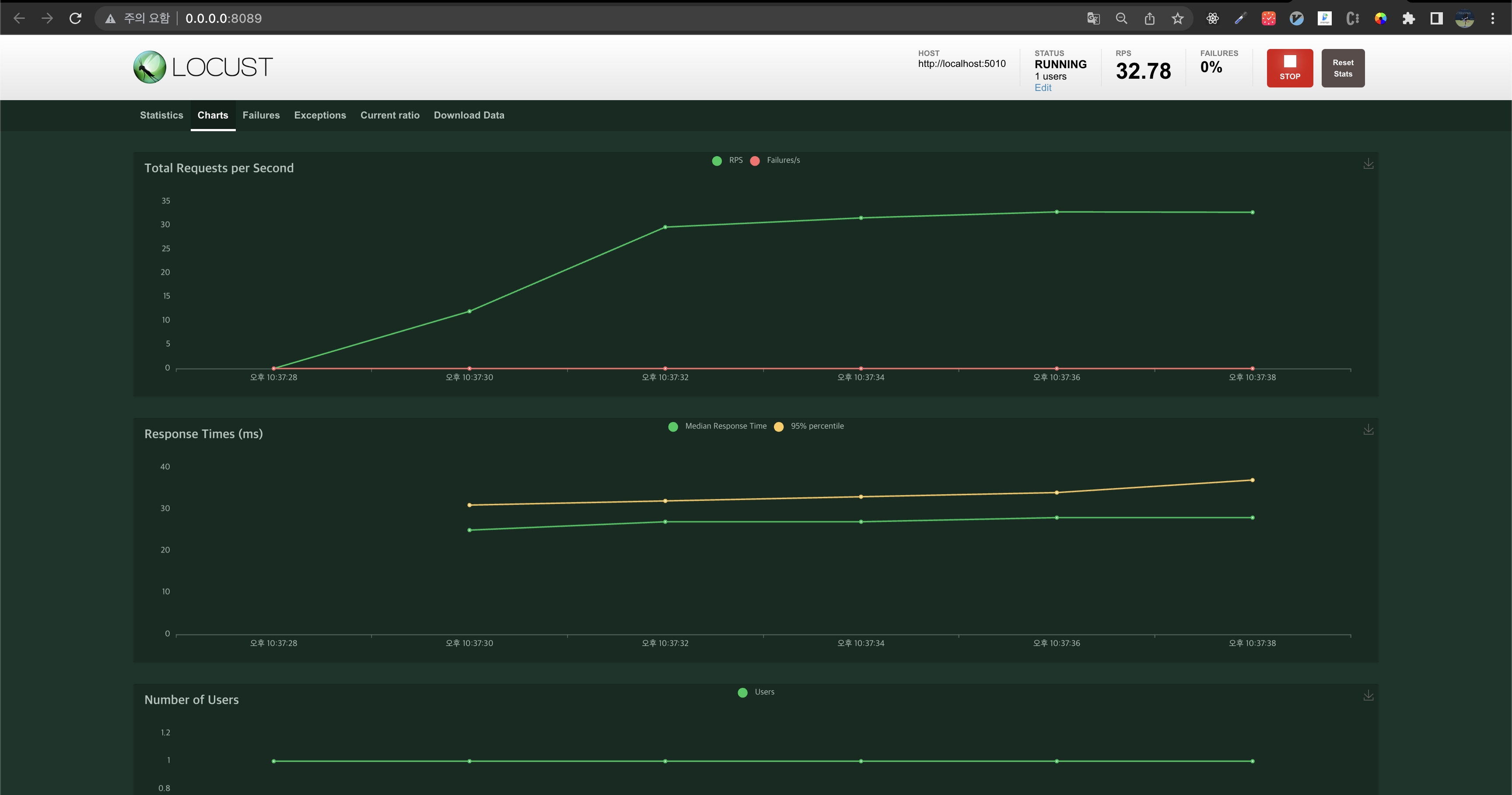
그리고 K8s에 업로드한 Pod의 Log를 확인해보자.
<문서/locust.mov>
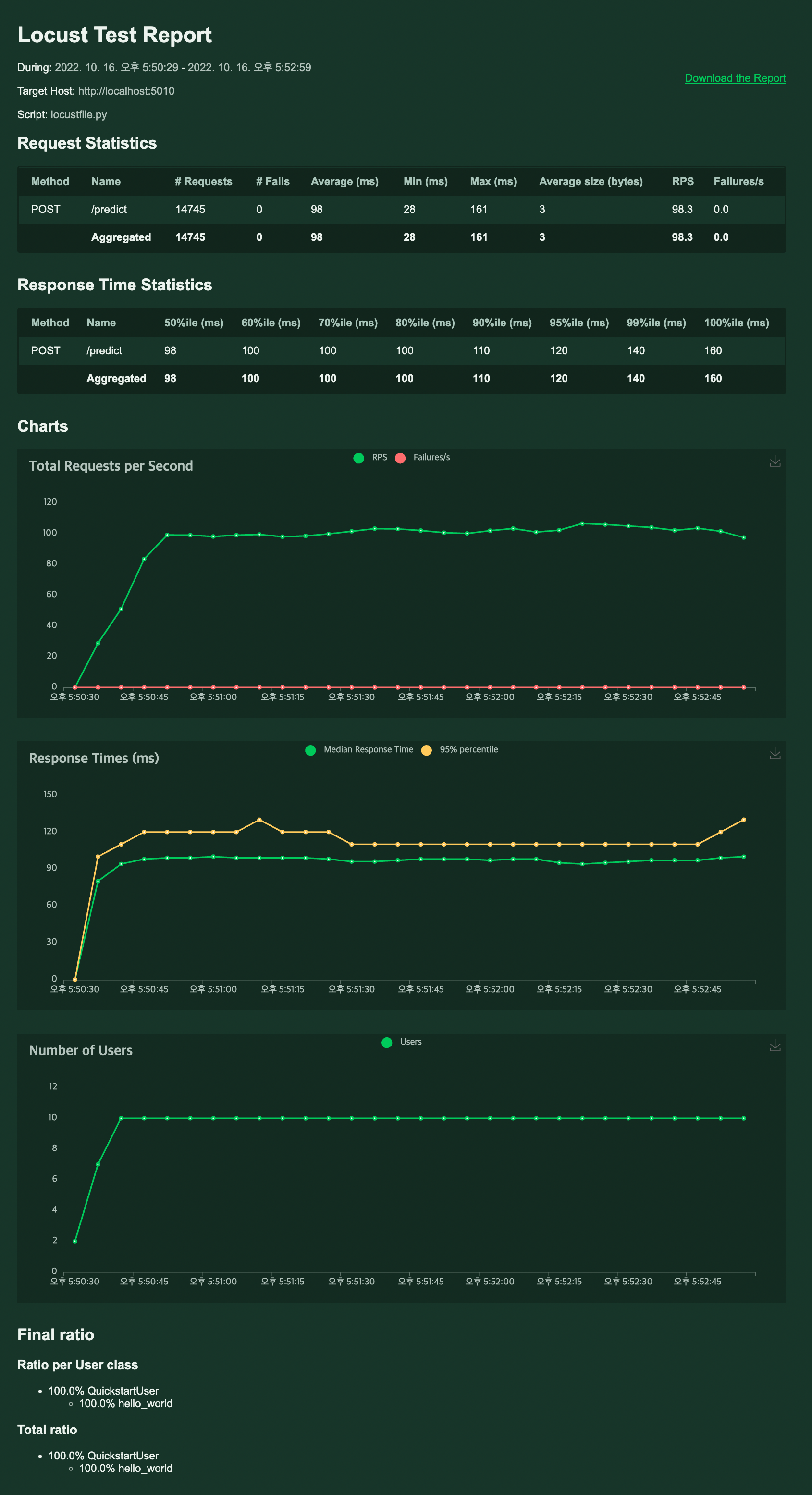
이제 마지막으로 Number of Users를 10으로 두고 최대 RPS를 측정해봄으로써 성능 테스트를 마무리한다.
BentoML 1.0.7
1. 모델 학습
앞선 0.13.1 버전과 같은 데이터셋, 모델을 이용해 모델 서빙을 해야한다. 데이터셋을 불러오고 모델을 정의한 뒤 학습까지는 동일하다.
# train.py import bentoml from sklearn import svm from sklearn import datasets # Load training data set iris = datasets.load_iris() X, y = iris.data, iris.target # Train the model clf = svm.SVC(gamma='scale') clf.fit(X, y) # Save model to the BentoML local model store saved_model = bentoml.sklearn.save_model("iris_clf", clf) print(f"Model saved: {saved_model}") # Model saved: Model(tag="iris_clf:zy3dfgxzqkjrlgxi")
실행
❯ python train.py # Model saved: Model(tag="iris_clf:skji2zcnjca4josw")
2. 모델 서빙 - 로컬 배포
아래 코드를 보면 많이 다른 것 같지만 BentoService를 상속받아 클래스를 정의하여 API를 메소드에 정의한 것(0.13.1)과 많이 다르지 않다. Service의 객체로 svc를 만들고 svc에 api 데코레이터로 함수를 감싸면 Service의 메소드로 정의된다. 조금 더 간소화 된 것으로 보인다.
import numpy as np import bentoml from bentoml.io import NumpyNdarray iris_clf_runner = bentoml.sklearn.get("iris_clf:latest").to_runner() svc = bentoml.Service("iris_classifier", runners=[iris_clf_runner]) @svc.api(input=NumpyNdarray(), output=NumpyNdarray()) def predict(input_series: np.ndarray) -> np.ndarray: result = iris_clf_runner.predict.run(input_series) return result
그리고 위에서 보이는것 처럼 runner를 정의하였다. runner는 독립적으로 확장할 수 있는 산 단위를 나타낸다.(사실 어떤 의미인지 잘 모르겠다 ㅠㅠ)
서비스를 정의했으면 Bento로 빌딩해야한다. Bento는 서비스의 배포형식이다. 서비스를 실행하기 위한 소스코드, 모델파일, 종속성 사양들을 포함하는 파일이다. Bento로 빌드하기 위해선 bentofile.yaml 파일을 정의해야 한다.
service: "service:svc" # Same as the argument passed to `bentoml serve` labels: owner: suwan stage: dev include: - "*.py" # A pattern for matching which files to include in the bento python: packages: # Additional pip packages required by the service - scikit-learn==1.0.2 - pandas==1.5.0
아래와 같이 총 3개의 파일이 필요하다.
1.0.7 ├── bentofile.yaml ├── service.py └── train.py
이제 Bento를 빌드하기 위해 아래 명령어를 입력하자.
❯ bentoml build
이제 아래 명령어로 로컬에서 배포할 수 있다.
bentoml serve iris_classifier:latest
앞선 0.13.1 버전에선 5000번 포트가 열렸었는데, 이번엔 3000번 포트가 열린다. 나중에 K8s의 Deployment에서 contaienrPort를 변경해주자.
http://localhost:3000/ 로 이동하면 아래와 같은 Swagger UI를 볼 수 있다.
3. 모델 서빙 - 쿠버네티스 배포
이제 쿠버네티스에 올리기 위한 도커 이미지 생성만이 남았다. 0.13.1 과 마찬가지로 docker build 명령어를 수행하면 되지만 bentoml 에서 제공하는 containerize 명령어로 도커 이미지를 생성할수도 있다.
bentoml containerize iris_classifier:latest docker tag iris_classifier ssuwani/iris-classifier:1.0.7 # 앞선 0.13.1 버전으로 테스트할 땐 0.13.1로 이미지 태그를 설정했다면 좋았을 듯,, # docker login docker push ssuwani/iris-classifier:1.0.7
그러면 아래와 같이 1.0.7 버전의 도커 이미지가 업로드 된 걸 확인할 수 있다.
1.0.7 버전에선 기본적으로 BentoML을 위한 서비스 포트가 3000번이여서 Deployment와 Service의 포트를 변경해주었다.
#iris-classifier.yaml apiVersion: v1 kind: Service metadata: labels: app: iris-classifier name: iris-classifier spec: ports: - name: predict port: 5010 targetPort: 3000 # 변경한 부분 selector: app: iris-classifier type: LoadBalancer --- apiVersion: apps/v1 kind: Deployment metadata: labels: app: iris-classifier name: iris-classifier spec: selector: matchLabels: app: iris-classifier template: metadata: labels: app: iris-classifier spec: containers: - image: ssuwani/iris-classifier:1.0.7 imagePullPolicy: IfNotPresent name: iris-classifier ports: - containerPort: 3000 # 변경한 부분 resources: requests: memory: "1Gi" cpu: "1" limits: memory: "1Gi" cpu: "1"
Resources의 memory와 cpu는 기존과 동일하게 설정하였다.
kubectl apply -f iris-classifier.yaml위 명령어로 배포한 뒤 http://localhost:5010/ 로 이동하면 아래와 같은 화면을 볼 수 있다.
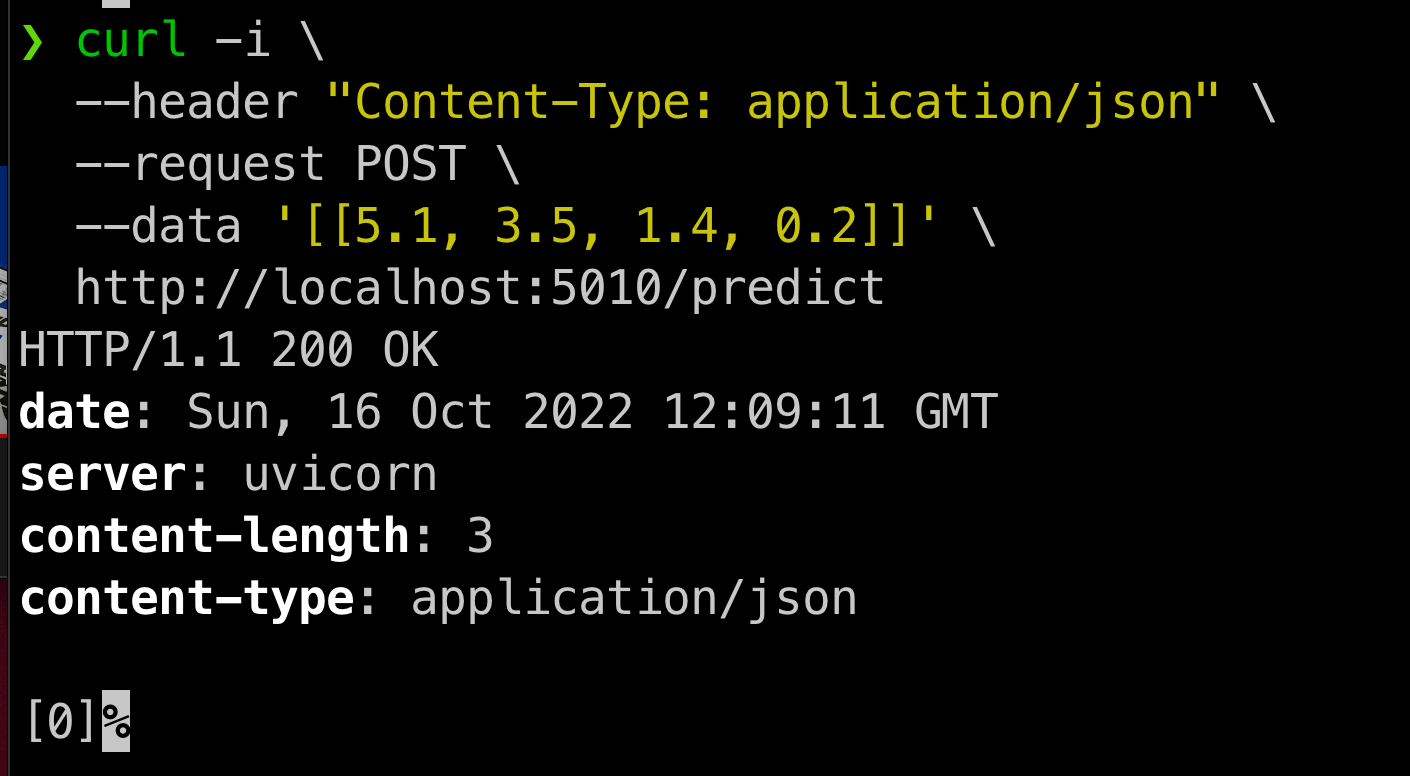
curl 명령어로 잘 동작하는지 확인해보자.
curl -i \ --header "Content-Type: application/json" \ --request POST \ --data '[[5.1, 3.5, 1.4, 0.2]]' \ http://localhost:5010/predict
4. 성능 테스트
잘 동작하는 것을 확인했으니 locust로 부하테스트를 해보자. 이전에 사용했던 [locustfile.py](http://locustfile.py) 를 사용하면 된다.
from locust import HttpUser, task, between class QuickstartUser(HttpUser): @task def hello_world(self): self.client.post("/predict", data='[[5.1, 3.5, 1.4, 0.2]]')
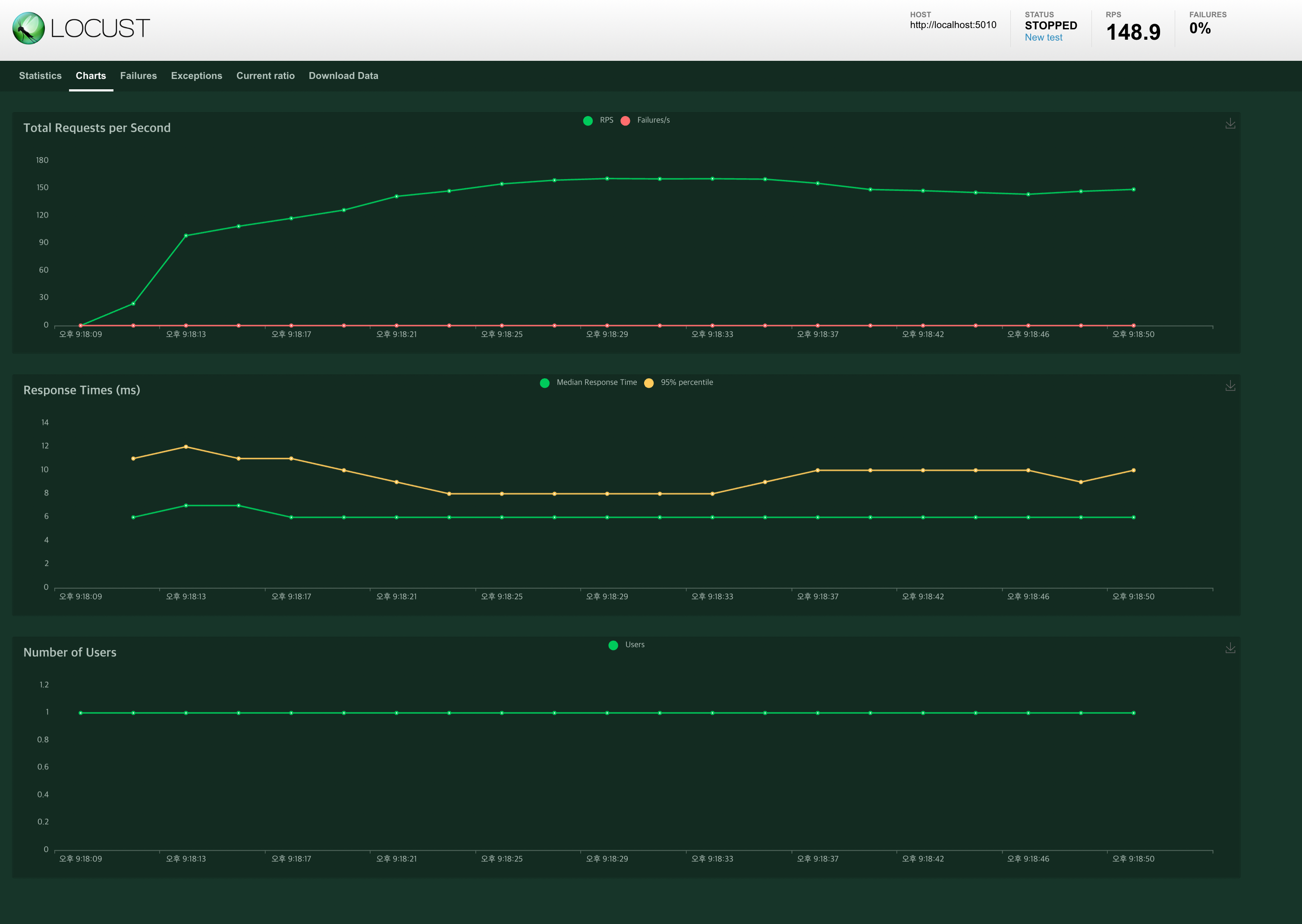
먼저 User 1명일 때 RPS가 얼마까지 올라가는지 확인해보자.
160RPS까지 올라가는 것을 확인했다.
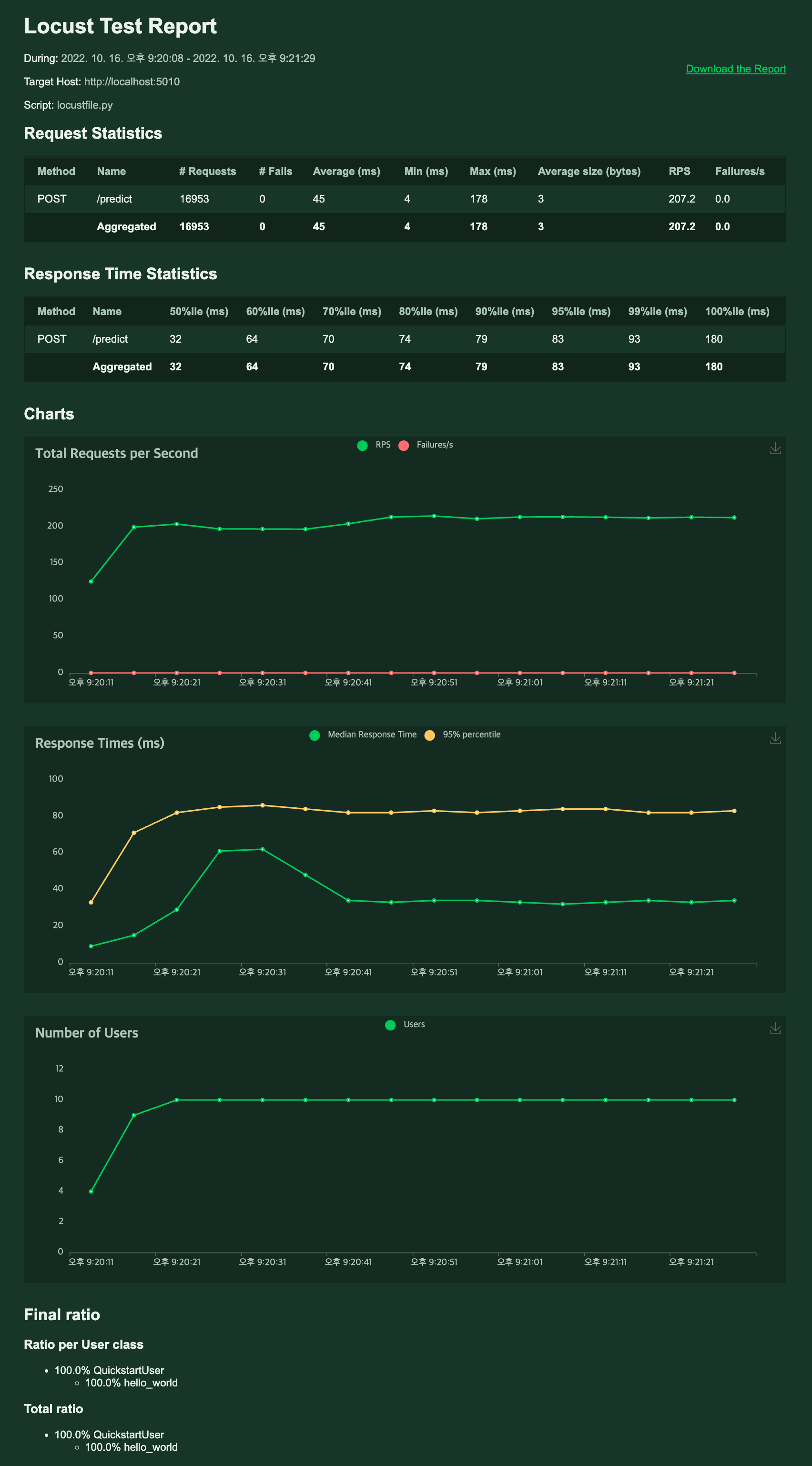
이제 User 10명일 경우는 얼마까지 올라가는지 확인해보자. 0.13.1 일때는 최대 110 정도까지 나왔었다.
안정적으로 200이상의 RPS를 확인할 수 있다.
결론
SVM이라는 아주 작은 모델로 테스트하였기 때문에 성능의 향상을 기대하기 힘들거라 생각했다. 하지만 약 2배정도의 성능 향상이 있었고 API를 위한 Service를 정의함에 있어서도 1.X 버전이 더 직관적이라는 생각이 든다. Yatai를 모한 모델 레지스트리 관리 및 쿠버네티스에 배포도 손쉽게 할 수 있기 때문에 검토를 고려하지 않을 이유가 없다고 생각된다.