Apache spark에서는 데이터를 다루기 위해 아래 3가지 추상화 개념을 제공합니다.
- RDD (Resilient Distributed Datasets)
- DataFrames
- Datasets
이 중 RDD에 대한 설명과 예제를 통해 이해해보고자 합니다.
정의
RDD는 Spark의 기본 데이터 구조로 병렬로 처리할 수 있는 불변 분산 객체 컬렉션
특징
- 메모리 내에서 처리 연산을 지원함
- 기존 map reduce 파일 시스템과 비교했을 때의 장점
- 생성되면 수정할 수 없음
- 기존 RDD를 수정하는 게 아니라 새로운 RDD를 생성함. (불변성)
- RDD는 장애로부터 쉽게 복구할 수 있음
- 위 불변성 덕분에 RDD 복구가 쉽고 분산 환경에서 처리되기에 Node A에서 문제시 Node B에서 수행 가능함
- Laze Evaluation
- Action 연산자를 만나야 작업을 수행함 (Tranformation 연산은 아무리 쌓여도 실행하지 않음)
- 컴파일 시 타입 체크
- 실행 전 에러를 조기 발견할 수 있음
연산
Transformation 연산
- map, filter, distinct, union, intersection
- Return: RDD
Action 연산
- collect, count, top(num), takeOrdered(num), reduce(func)
- Return: 실행 결과
예제
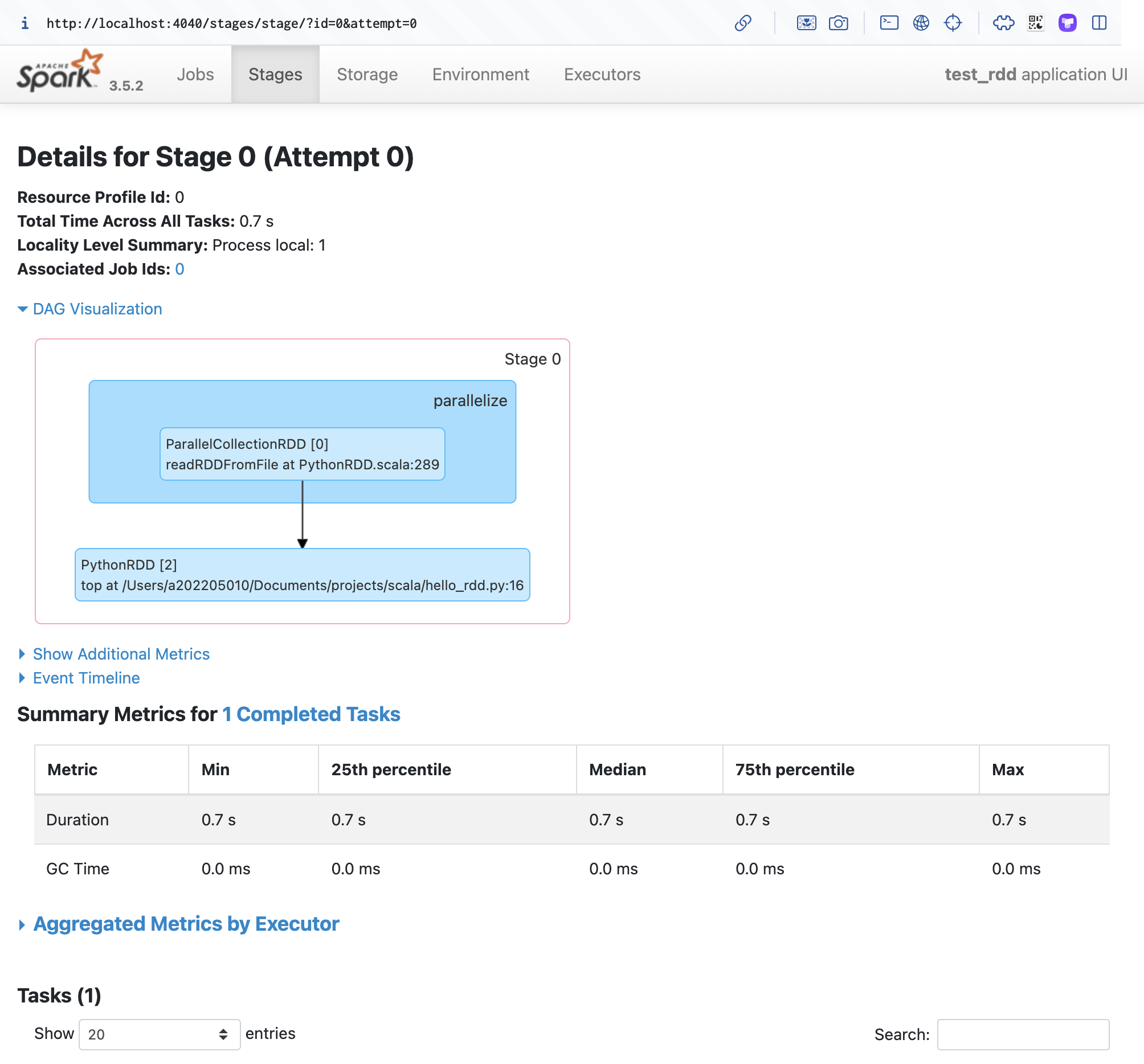
예제 데이터로부터 RDD를 생성한 뒤 transformation 연산 & Action 연산을 수행해보고자 합니다.
그리고 Spark WebUI를 통해 수행 작업을 시각화해서 확인해 봅니다.
from pyspark import SparkContext, SparkConf conf = SparkConf().setAppName("test_rdd").setMaster("local") sc = SparkContext(conf=conf) data = [1, 2, 3, 4, 5] distData = sc.parallelize(data) # transformation added_distData = distData.map(lambda x: x+1) # action result = added_distData.top(3) while True: pass # web ui 확인
http://localhost:4040 에서 Stage 확인
