아래 내용은 도서 "트랜스포머를 활용한 자연어 처리"의 내용을 실습한 내용입니다.
트랜스포머를 활용해서 특정 텍스트에 대한 감성을 분류하는 모델을 손쉽게 학습하고자 한다.
데이터셋 준비하기
감성을 분류하는 모델 학습을 위해 특정 데이터에 대한 감성이 분류되어 있는 데이터셋이 준비되어야 한다.
HuggingFace에서 제공하는 datasets 라이브러리를 사용하면 손쉽게 트윗에 대한 감성이 분류되어 있는 데이터셋을 불러올 수 있다.
from datasets import load_dataset
emotions = load_dataset("emotion")
emotions["train"].features["label"]
# ClassLabel(names=['sadness', 'joy', 'love', 'anger', 'fear', 'surprise'], id=None)'sadness', 'joy', 'love', 'anger', 'fear', 'surprise'와 같이 분류되어 있는 데이터셋이다.
사전 훈련된 모델 사용하기
AutoModel 클래스에서 사전 훈련된 모델의 가중치를 로드하는 from_pretrained() 메서드 사용할 수 있다.
사전 훈련된 모델은 distilbert-base-uncased라는 BERT와 유사한 성능을 제공하면서 더 작고 빠른 모델을 사용하자
from transformers import AutoModel
import torch
model_ckpt = "distilbert-base-uncased"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = AutoModel.from_pretrained(model_ckpt).to(device)AutoModel 클래스는 토큰 인코딩을 임베딩으로 변환한 다음 인코더 스택에 통과시켜 은닉 상태를 반환한다.
- Tokenizer를 불러온다. (distilbert 모델의 tokenizer)
- 문자열을 인코딩한다.
- 모델에 입력해서 은닉 상태를 반환한다. (forward pass)
# 1. Tokenizer를 불러온다
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
# 2. 문자열을 인코딩 한다.
text = "this is a text"
inputs = tokenizer(text, return_tensors="pt")
print(f"입력 텐서 크기: {inputs['input_ids'].size()}")
# 3. 인코딩된 문자열을 모델에 넣는다.
inputs = {k: v.to(device) for k, v in inputs.items()}
with torch.no_grad():
outputs = model(**inputs)
print(f"outputs: {outputs}")
print(f"last hidden state: {outputs.last_hidden_state.size()}")
# 입력 텐서 크기: torch.Size([1, 6])
# outputs: BaseModelOutput(last_hidden_state=tensor([[[-0.2535, -0.1091, 0.0759, ..., -0.1054, 0.2257, 0.4615],
# [-0.7154, -0.2742, -0.0954, ..., -0.3597, 0.5174, 0.3450],
# [-0.4100, -0.2195, 0.1850, ..., -0.0136, 0.1607, 1.0422],
# [-0.2523, -0.0254, 0.2472, ..., -0.1637, 0.0865, 1.0516],
# [-0.0570, -0.1057, 0.0662, ..., 0.0584, 0.1034, 0.2971],
# [ 0.9184, 0.1577, -0.4105, ..., 0.1509, -0.7327, -0.1572]]]), hidden_states=None, attentions=None)
# last hidden state: torch.Size([1, 6, 768])입력 텐서 크기가 torch.Size([1, 6])에서 1은 batch_size를 의미하고 6은 텍스트를 토큰으로 변경했을 때의 토큰 수를 의미한다.
아래와 같이 토큰화되었음을 유추할 수 있다.
- [CLS]: 시작 토큰
- this
- is
- a
- text
- [SEP]: 종료 토큰
tokenizer.convert_ids_to_tokens(inputs["input_ids"][0]) 이 코드를 통해 실제로 토큰을 확인할 수도 있다.
또한, last hidden state가 torch.Size([1, 6, 768])에서 6개의 토큰마다 768차원의 벡터가 반환된 것을 알 수 있다.
분류 작업에선 보통 [CLS] 토큰에 연관된 은닉 상태를 입력 특성으로 사용한다.
앞서 수행한 내용을 하나의 함수로 만들어서 배치 데이터에 대해 처리할 수 있도록 하자.
def extract_hidden_states(batch):
inputs = {k:v.to(device) for k, v in batch.items() if k in tokenizer.model_input_names}
with torch.no_grad():
last_hidden_state = model(**inputs).last_hidden_state
return {"hidden_states": last_hidden_state[:, 0].cpu().numpy()}또한, emotions 데이터셋에 대해 모든 데이터를 할 수 있도록 tokenize 함수도 정의하자.
- padding을 True로 하면 배치에 있는 가장 긴 샘플 크기에 맞춰서 토큰 수가 결정된다.
- truncate를 True로 하면 모델의 최대 문맥 크기에 맞춰 샘플을 잘라낸다.
def tokenize(batch):
return tokenizer(batch["text"], padding=True, truncation=True)
emotions_encoded = emotions.map(tokenize, batched=True, batch_size=None)이제 데이터셋에 대해 한번에 은닉 상태를 추출하자.
batch_size를 지정하지 않았기 때문에 default인 1000개씩 hidden_state를 계산한다.
emotions_encoded.set_format(type="torch", columns=["input_ids", "attention_mask", "label"])
emotions_hidden = emotions_encoded.map(extract_hidden_states, batched=True)이제 각 Text에 대해 distilbert를 통해 은닉 상태를 추출했다. 이는 각 text의 특성을 가지고 있는 벡터가 반환되었다고 할 수 있다.
이 은닉 상태를 가지고 Logistics Regression 모델을 훈련하자.
from sklearn.linear_model import LogisticRegression
lr_clf = LogisticRegression(max_iter=1000)
lr_clf.fit(emotions_hidden["train"]["hidden_states"], emotions["train"]["label"])
lr_clf.score(emotions_hidden["test"]["hidden_states"], emotions["test"]["label"])
# 0.627위 결과와 DummpyClassifier와의 비교 (가장 빈도가 높은 라벨을 선택하는 모델)
from sklearn.dummy import DummyClassifier
dummy_clf = DummyClassifier(strategy="most_frequent")
dummy_clf.fit(emotions_hidden["train"]["hidden_states"], emotions["train"]["label"])
dummy_clf.score(emotions_hidden["test"]["hidden_states"], emotions["test"]["label"])
# 0.3475성능이 그리 나쁘지 않다는 걸 알 수 있다.
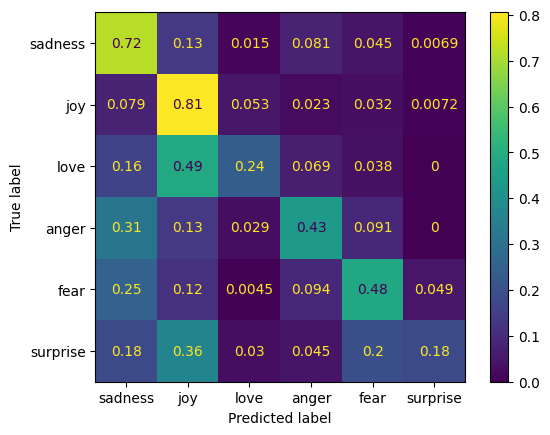
confusion matrix를 확인해 보자.
from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix
def plot_confusion_matrix(y_preds, y_true, labels):
cm = confusion_matrix(y_true, y_preds, normalize="true")
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
return disp.plot()
y_preds = lr_clf.predict(emotions_hidden["test"]["hidden_states"])
labels = emotions["train"].features["label"].names
plot_confusion_matrix(y_preds, emotions["test"]["label"], labels)