지금까지 토픽에 메시지를 생성하고 소비했다. users라는 토픽에 아래와 같은
메시지를 생성했고 해당 메시지들을 소비했었다.
{
"userid": <유저 번호>,
"gender": <유저 성별>,
"username": <유저 이름>
}위와 같은 형태로 입력해 주기로 프로듀서와 컨슈머가 약속했지만 갑자기 알 수 없는
이유로 토픽에 메시지로 “Hello”가 입력되면 시스템 장애가 발생할 것이다.
Schema Registry를 통해 검증된 메시지만 생성되도록 하자.
대상 독자
- 안전한 메시징 시스템을 구축하고자 하는 개발자.
Steps
- Schema 정의하기
- 토픽에 스키마 등록하기
- 메시지 생성하기
- 마무리
1. Schema 정의하기
Schema는 3가지 타입을 통해 정의할 수 있다.
- JSON
- Avro
- Protobuf
이 중 어떠한 것을 선택하든 상관은 없지만 Avro와 Protobuf를 사용하면 데이터를
이진화하여 저장하기에 데이터 크기가 작고 직렬화 및 역직렬화가 빠르게 진행된다.
이 글에선 Avro 타입으로
스키마를 정의할 것이다.
앞선 다룬 Users 토픽의 메시지 유형에 맞게 Avro 스키마를 정의하면 다음과 같다.
{
"type": "record",
"name": "UserInfo",
"namespace": "com.example",
"fields": [
{ "name": "userid", "type": "int" },
{ "name": "gender", "type": "string" },
{ "name": "username", "type": "string" }
]
}2. 토픽에 스키마 등록하기
Control Center에서 간단하게 스키마를 등록할 수 있다.
아래 사진과 같이 토픽을 선택한 뒤 Schema 탭에 이동해서 value의 스키마를 등록으로
이동

Avro 타입을 선택한 뒤 스키마를 입력하고 Validate를 통해 스키마를 검사한 뒤
Create를 통해 토픽에 스키마를 등록하자.

3. 메시지 생성하기
앞서서 스키마 레지스트리를 사용하지 않고 Produce 할 때와 많이 다르지 않다.
메시지를 생성하는 것은 같지만 메시지가 Avro 타입으로 직렬화를 진행한 뒤 생성하는
것이다.
그리고 사실 기존에도 json.dumps(message)를 통해 직렬화를 했었다. 이를
avro_serializer(message)와 같은 형태로 직렬화를 진행한 뒤 Produce 할 것이다.
여기서 주의해야 할 점은 “어떠한 스키마로 메시지를 직렬화할 것인가”이다.
방법은 크게 두 가지가 있다.
- 애플리케이션 내에 avro schema 파일을 관리
- Schema Registry Client로부터 스키마 가져오기
흔히 사용하는 방법은 첫 번째인 듯하나, 나는 두 번째 방법도 괜찮다고 생각한다.
왜냐하면
- 스키마가 업데이트되면 schema_id는 달라진다.
- 두 번째 방식은 schema 코드를 여러 군데에서 관리할 필요가 없다.
from confluent_kafka import Producer
from confluent_kafka.schema_registry import SchemaRegistryClient
from confluent_kafka.schema_registry.avro import AvroSerializer
from confluent_kafka.serialization import MessageField, SerializationContext
schema_registry_client = SchemaRegistryClient({"url": "http://localhost:8081"})
schema_str = schema_registry_client.get_schema(schema_id=1).schema_str
avro_serializer = AvroSerializer(schema_registry_client, schema_str)
producer = Producer({"bootstrap.servers": "localhost:9092"})
topic_name = "users"
message = {"userid": 4, "gender": "FEMALE", "username": "광수"}
producer.produce(
topic=topic_name,
value=avro_serializer(
message, SerializationContext(topic_name, MessageField.VALUE)
),
)
producer.flush()메시지가 잘 생성된 것을 확인할 수 있다.

그러면, 지정된 스키마가 아닌 메시지를 produce 한다면 어떻게 될까? 예시 메시지는
다음과 같다.
message = {"id": 4, "gender": "FEMALE", "username": "광수"}등록된 스키마엔 userid이지만 id라고 실수로 기입했다고 가정하자.
produce를 시도하게 되면 직렬화 단계에서 실패하고 userid에 대한 값이 없고 디폴트
값도 없다고 안내하고 있다. (avro 스키마엔 default 값을 지정할 수 있다.)

4. 마무리
우리가 지금까지 수행한 단계는 다음과 같다.
- Schema Registry에 스키마를 등록했고
- Producer는 등록된 스키마를 읽어온 뒤
- 메시지를 생성할 때 직렬화를 수행한 뒤
- 메시지를 생성했다.
앞서 userid를 id로 실수로 기입한 시나리오에서 produce 전 직렬화 단계에서 실패했다. 하지만 이는 토픽에 지정되어 있는 스키마와는 별개의 validation이다.
스키마를 관리하는 방법이 로컬에 .avsc 파일을 통해 관리하는 방법도 있다고 했는데 이렇게 관리할 경우 로컬에 스키마와 실제 토픽에 지정되어 있는 스키마 간에 상이할 수 있다. 이 경우 produce 전 직렬화는 성공하더라도 produce는 되어선 안된다.
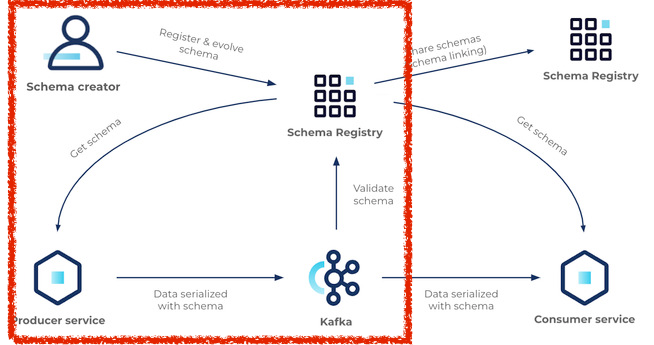
카프카에선 아래 그림처럼 produce 시 Schema Registry와 통신하여 validation을 진행한 뒤 메시지가 생성된다.