1. Why mlflow

이 그림을 엄청 많이 봤다. 이 그림을 통해 보통 하고자 하는 말은 ML 시스템을 운영하기 위해 ML Code 이외에도 다양한 컴포넌트가 많다는 것이다. 하지만, 머신러닝 애플리케이션에서 가장 핵심적인 컴포넌트는 모델이라고 생각한다. 이 핵심적인 "모델"이 어떻게 학습되었고 어떻게 저장되었으며 어떻게 배포되어 있는지 이를 제일 잘할 수 있도록 설계된 툴이 MLflow가 아닐까.
2. What we need
mlflow의 설명을 보자, "An open source platform for the machine learning lifecycle". 모델의 모든 생애주기 관리하기 위한 플랫폼으로서 mlflow는 발전하고 있다. 그렇게 된다면 유지관리가 엄청 편해지겠지만 그렇기엔 아직 성숙도가 부족하다고 생각한다. 그래서 mlflow를 플랫폼으로서 사용하는 게 아니라 하나의 툴로서 사용하고자 한다.
내가 생각하는 mlflow가 가장 잘하고 다른 툴로 대체하기 힘든 영역이 Tracking과 Model Registry이다.
- Tracking
- 모델 학습 주기에서 학습에 사용된 parameter와 모델의 metric 등을 로깅해 준다.
- Model Registry
- 모델을 저장할 수 있는 저장소이고 모델의 버전 관리 및 Stage 관리를 할 수 있다.
3. Install
설치에 관련된 이야기를 잠깐만 해보자면, mlflow는 parameter, metric 그리고 model registry에 사용된 metadata 들을 저장할 Database 사용을 권장한다. 또한 Artifact와 같은 무거운 파일 같은 경우 원격 저장소를 사용하는 걸 권장한다. (ex. s3)
s3 같은 경우 minio를 사용해 대체할 수 있다. 하지만 로컬에서 배포하여 테스트하고자 하는 경우 DB와 minio를 띄우는 것이 너무 귀찮기 때문에 누군가 만들어 놓은 docker-compose를 사용해 실행시켜주기만 하면 된다.
https://github.com/sachua/mlflow-docker-compose 여기를 참고해 설치하자. (mlflow/requirements.txt를 수정해 mlflow 버전을 제어할 수 있다.)
사진과 같이 s3://mlflow/0과 같이 나와야 한다. (참고로 0은 실험 ID)
또한 models 탭을 눌렀을 때 에러가 나지 않아야 한다. (model registry는 DB의 연결에 의존성이 있어서 models 탭 자체에 접근이 안 됨)
4. Do
Tracking의 경우 너무너무 중요하고 꼭 필요한 내용이지만 mlflow.autolog()만으로도 많은 영역이 커버되고 추가로 필요한 부분을 찾아서 로깅하면 된다고 생각한다. 간단한 Iris 분류 문제를 위한 모델을 MLflow로 Tracking 해보자.
import mlflow from sklearn import datasets, model_selection, svm mlflow.set_experiment("iris") mlflow.autolog() iris = datasets.load_iris() X, y = iris.data, iris.target train_x, test_x, train_y, test_y = model_selection.train_test_split(X, y, test_size=0.2, random_state=42) clf = svm.SVC() clf.fit(X, y) score = clf.score(test_x, test_y)
이를 그대로 실행하면 로컬 환경에 mlflow 폴더가 생기고 로깅이 될 것이다. 일반적으로 mlflow를 통해 원하는 것은 모델 학습을 한 곳에서 비교 및 모니터링하는 것이다. 이를 위해선 앞서 배포한 mlflow server url인 http://localhost:5000를 MLFLOW_TRACKING_URI라는 이름의 환경변수로 등록해줘야 한다.
export MLFLOW_TRACKING_URI=http://localhost:5000 export MLFLOW_S3_ENDPOINT_URL=http://localhost:9000 # s3 url도 추가
또한 s3(minio)에 접근하기 위한 권한도 입력해줘야 한다. (아래 코드는 기존에 aws를 위한 default profile이 있다면 덮어씌워지니 주의하자)
cat <<EOF > ~/.aws/credentials [default] aws_access_key_id=minio aws_secret_access_key=minio123 EOF
이제 실행하면 아래와 같이 나온다.
위 사진엔 mlflow.autolog()를 통해 로깅된 실험에 대한 정보들이 많이 있다. 그중 일반적으로 배포를 위해 눈여겨보는 내용은 metrics와 모델이 어디에 저장되어 있느냐이다. 그러나 mlflow를 model registry로 사용하게 된다면 우리는 특정 모델의 Stage를 바라보기만 하면 된다.
model registry에 등록하는 방법은 두 가지이다.
- UI에서 Register Model 버튼 (수동)
- mlflow client를 통해 등록 (자
동)
아래 방법이 더 이상적이라 생각한다. metric을 보고 특정 threshold 혹은 이전 모델의 metric과 비교하는 등의 로직을 설정한 뒤 충족된다면 Model Registry에 등록되게 하면 된다.
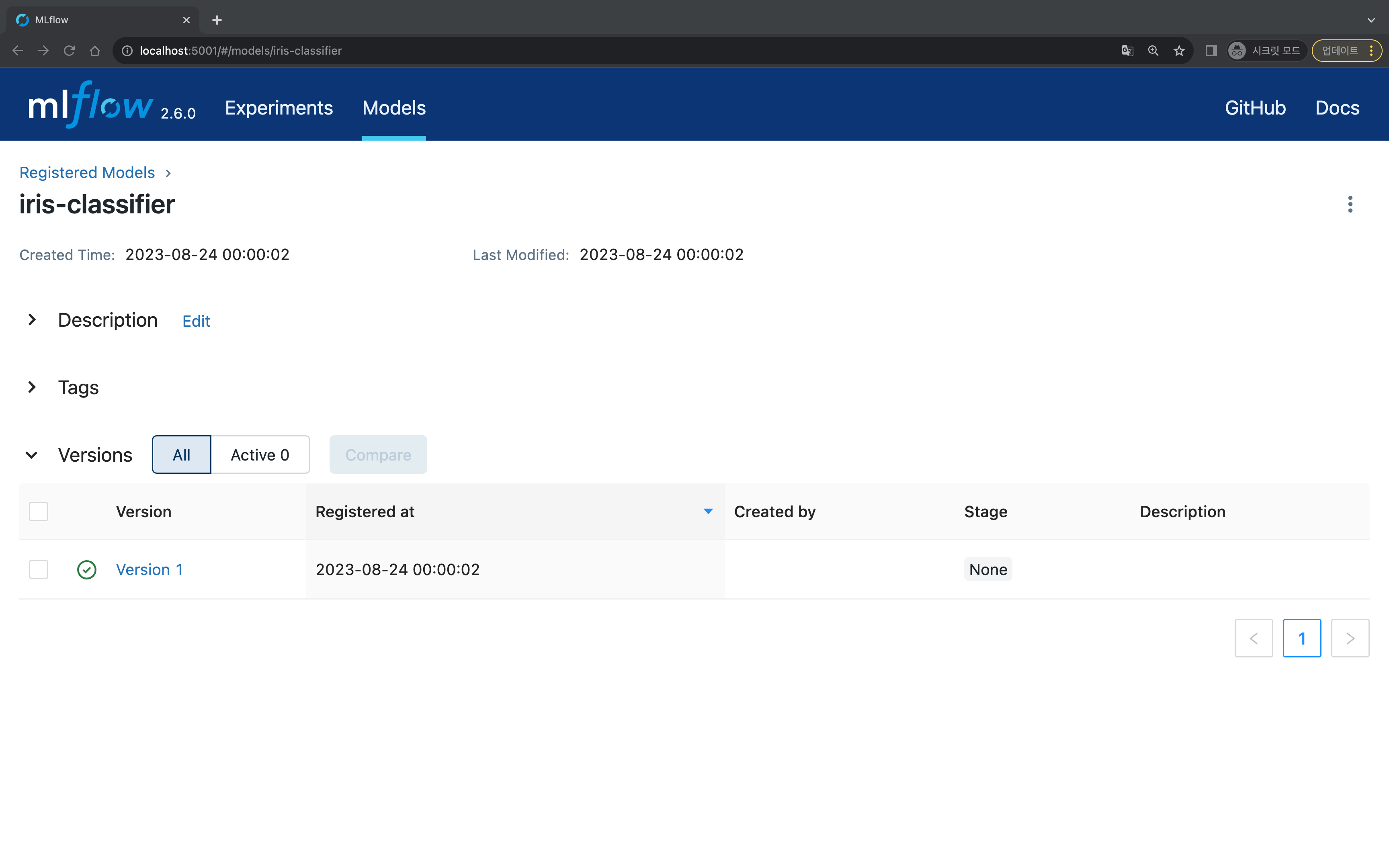
나는 앞서 학습한 모델을 통해 UI에서 등록하였다. (model: iris-classifier)
Version 1이 생성되었고 현재 Stage는 None으로 확인된다.
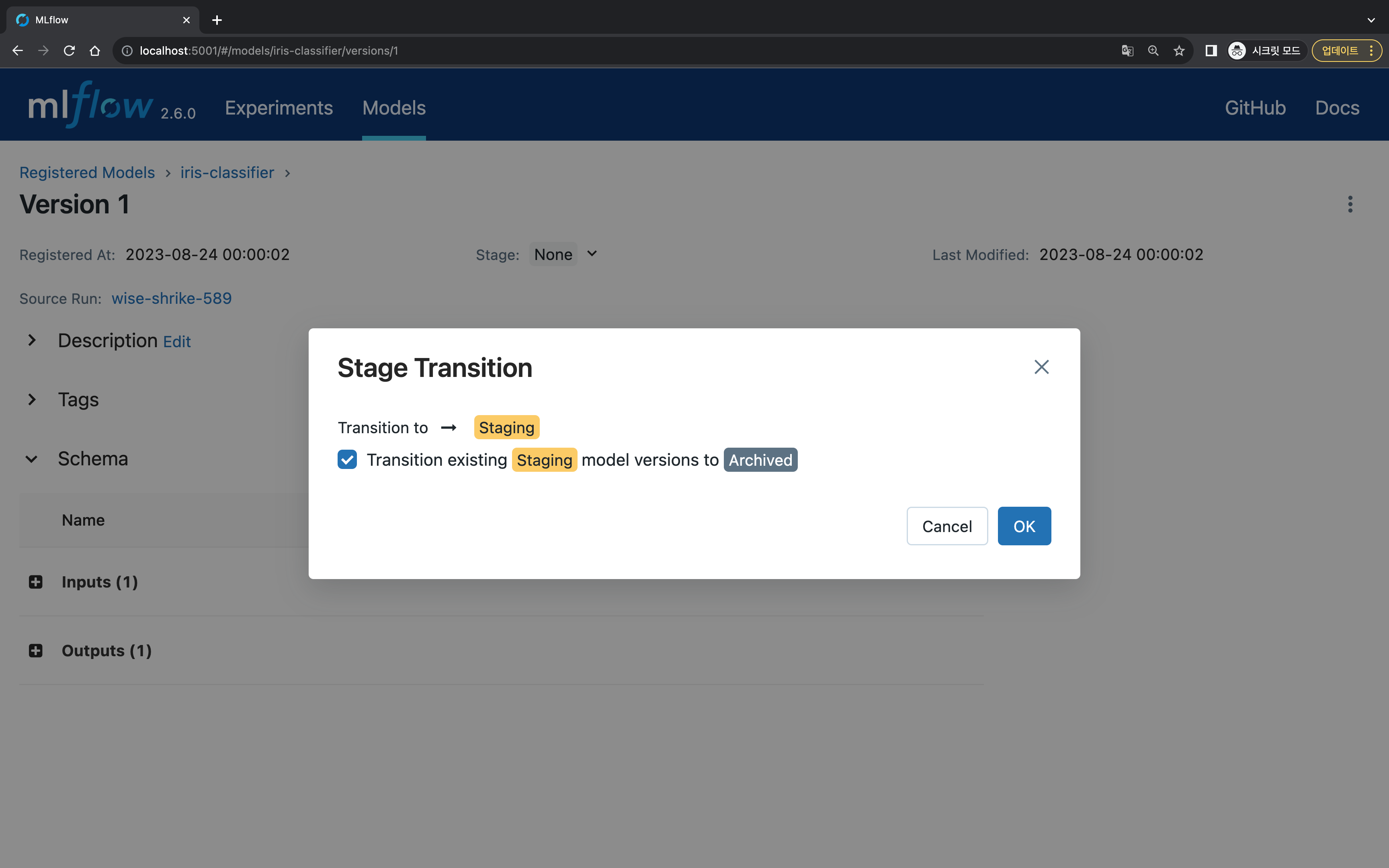
Staging으로 변경해 보자.
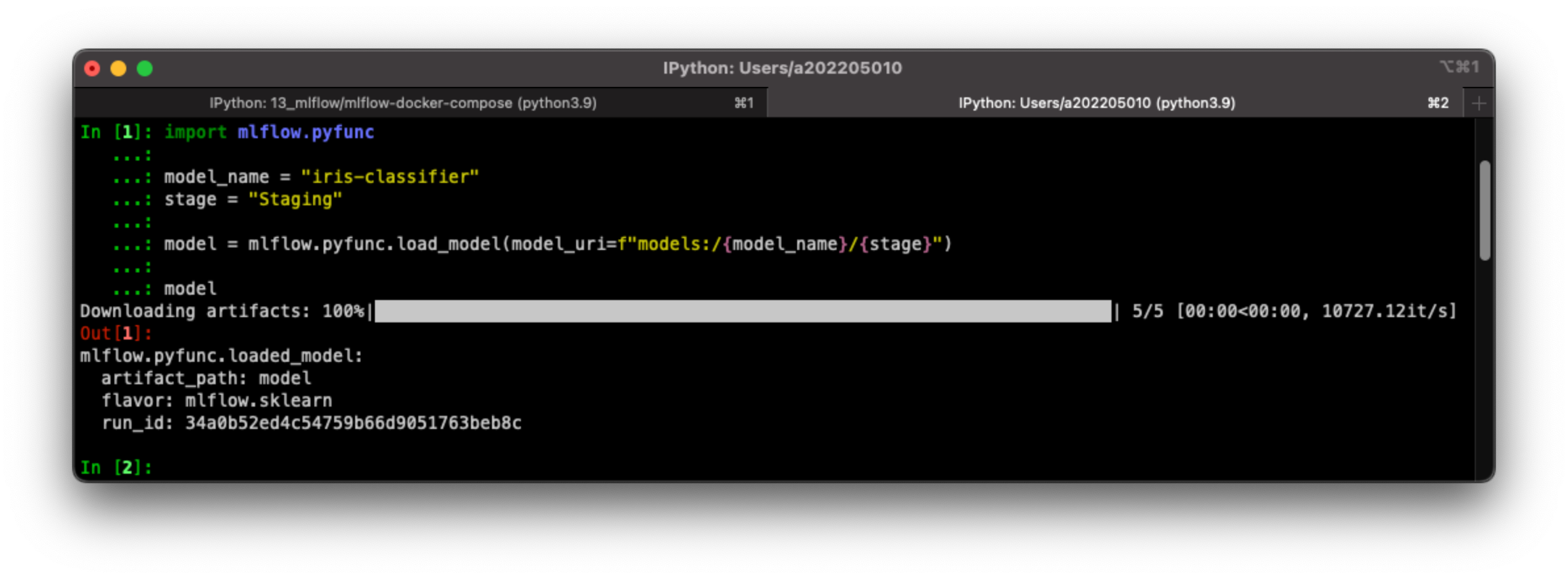
이제 아래와 같이 불러올 수 있다.
import mlflow.pyfunc model_name = "iris-classifier" stage = "Staging" model = mlflow.pyfunc.load_model(model_uri=f"models:/{model_name}/{stage}") model